
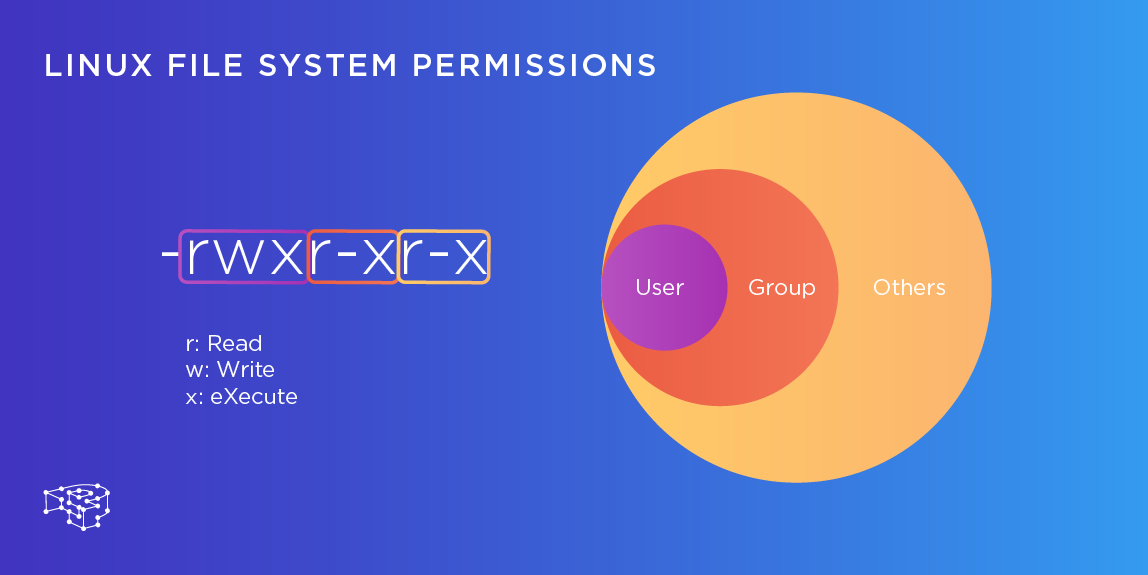
Tổng quan về file trên Linux
Hệ điều hành Linux quản lý nhiều loại file khác nhau, mỗi loại có đặc điểm và mục đích sử dụng riêng biệt. Dưới đây là một cái nhìn tổng quan về các loại file trên Linux:
Regular File (File thông thường): Đây là loại file phổ biến nhất. Nó bao gồm các file văn bản, file thực thi (executable files), file đa phương tiện, v.v. File thông thường có thể chứa dữ liệu, như văn bản hoặc mã nhị phân. Ví dụ: Một tài liệu văn bản như report.txt, một tập tin mã nguồn như main.c, hoặc một file thực thi như /bin/bash.
Directories File (File thư mục): Trong Linux, thư mục cũng được coi như là một loại file. Thư mục chứa danh sách các file khác và thư mục con. Nó giúp tổ chức và quản lý file một cách hiệu quả. Ví dụ: Thư mục /home/username chứa các file và thư mục con của người dùng, hoặc thư mục /etc chứa các file cấu hình hệ thống.
Character Device File (File thiết bị ký tự): Đây là các file đặc biệt mà thông qua đó hệ thống và các chương trình có thể tương tác với các thiết bị phần cứng. Chúng là giao diện cho các thiết bị như bàn phím, chuột, và các thiết bị khác không sử dụng bộ nhớ đệm. Ví dụ: File /dev/tty đại diện cho thiết bị đầu cuối, hoặc file /dev/null mà bất kỳ dữ liệu nào được ghi vào đó sẽ bị “hủy”.
Block Device File (File thiết bị khối): Giống như Character Device File, nhưng chúng được dùng cho các thiết bị lưu trữ như ổ cứng, ổ SSD, v.v. Chúng làm việc với các khối dữ liệu (thường là 512 byte hoặc nhiều hơn) và thường có bộ nhớ đệm. Ví dụ: File /dev/sda đại diện cho ổ đĩa cứng đầu tiên, hoặc /dev/sdb1 cho phân vùng đầu tiên trên ổ đĩa thứ hai.
- Link Files (File liên kết): Trong Linux có hai loại liên kết: liên kết cứng (hard link) và liên kết mềm (symbolic link, hay symlink). Liên kết cứng trỏ trực tiếp đến dữ liệu của file gốc, trong khi liên kết mềm chỉ là một file tham chiếu đến đường dẫn của file gốc. Ví dụ:
- Liên kết cứng (Hard link): Tạo một liên kết cứng cho file data.txt tên là hardlink_data.
- Liên kết mềm (Symbolic link): Tạo một symlink shortcut_to_data trỏ đến data.txt.
Socket File (File socket): Đây là file đặc biệt được sử dụng để truyền dữ liệu giữa các quá trình. Chúng thường được dùng trong giao tiếp mạng hoặc giao tiếp giữa các quá trình (IPC). Ví dụ: File /var/run/docker.sock được sử dụng bởi Docker để giao tiếp giữa Docker daemon và các client.
- Pipe File (File pipe): File này được dùng để truyền dữ liệu từ một quá trình này sang quá trình khác. Một pipe thường được sử dụng trong các chuỗi lệnh shell, cho phép đầu ra của lệnh này trở thành đầu vào của lệnh tiếp theo. Ví dụ: Một named pipe (FIFO) như /tmp/my_pipe, được sử dụng để truyền dữ liệu giữa các quá trình khác nhau.
Hệ điều hành Linux, thông qua kernel của nó, cung cấp một bộ system call cơ bản để thực hiện việc đọc, ghi và thao tác với file. Các system call này rất quan trọng và được sử dụng rộng rãi trong lập trình Linux. Dưới đây là mô tả ngắn gọn về mỗi system call:
open():- Mục đích: Mở một file để đọc, ghi, hoặc cả hai.
- Cách sử dụng: Khi gọi
open(), bạn cần chỉ định đường dẫn của file và chế độ mở (ví dụ: chỉ đọc, chỉ ghi, đọc và ghi). Hàm này trả về một file descriptor (FD) mà sau này sẽ được sử dụng cho các thao tác trên file.
read():- Mục đích: Đọc dữ liệu từ một file.
- Cách sử dụng:
read()yêu cầu một file descriptor, một buffer nơi dữ liệu sẽ được đọc vào, và số lượng byte cần đọc. Hàm này trả về số byte thực sự đã đọc được.
write():- Mục đích: Ghi dữ liệu vào một file.
- Cách sử dụng: Tương tự như
read(),write()yêu cầu một file descriptor, một buffer chứa dữ liệu cần ghi, và số lượng byte cần ghi. Số byte đã ghi được trả về sau khi hàm thực thi.
lseek():- Mục đích: Thay đổi vị trí con trỏ file trong một file.
- Cách sử dụng:
lseek()cần một file descriptor, một offset và một hướng dẫn về cách thay đổi vị trí (ví dụ: từ đầu file, từ vị trí hiện tại, hoặc từ cuối file). Hàm này cho phép bạn di chuyển con trỏ đến một vị trí cụ thể trong file để đọc hoặc ghi.
close():- Mục đích: Đóng một file.
- Cách sử dụng:
close()chỉ yêu cầu một file descriptor. Khi một file không còn cần thiết nữa, hàm này sẽ được gọi để giải phóng tài nguyên và file descriptor.
Các system call này là nền tảng cho việc xử lý file trong Linux và là một phần không thể thiếu trong lập trình hệ thống. Chúng cho phép lập trình viên tương tác trực tiếp với hệ thống file và các thiết bị I/O mà không cần phải quan tâm nhiều đến chi tiết cấp thấp của hệ điều hành.
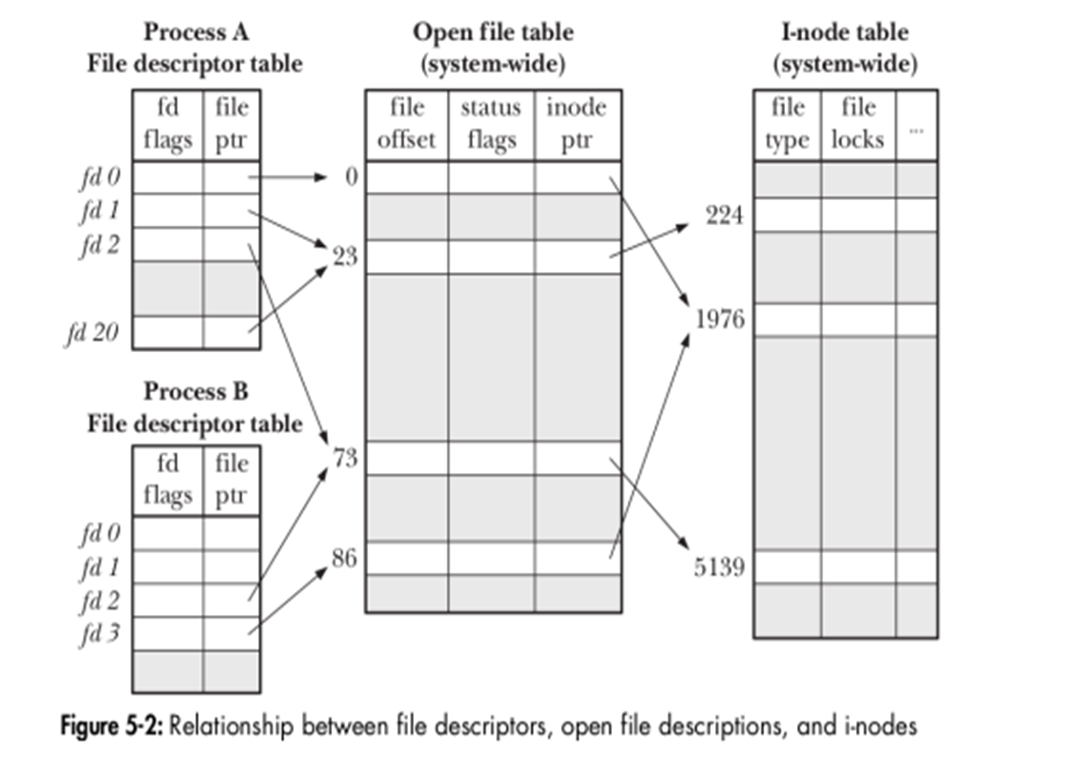
Trong hệ điều hành Linux, kernel quản lý tương tác giữa tiến trình và file thông qua ba bảng quan trọng: File Descriptor Table, Open File Table, và I-node Table. Mỗi bảng này có chức năng cụ thể:
- File Descriptor Table:
- Mỗi tiến trình trong Linux có một bảng File Descriptor riêng. Bảng này lưu trữ thông tin về các file mà tiến trình đó đang mở.
- Mỗi mục trong bảng là một File Descriptor (FD), là một số nguyên dùng để định danh và tham chiếu đến một file cụ thể mà tiến trình đang sử dụng.
- Khi một file được mở bằng lệnh
open(), một FD mới được tạo trong bảng này.
- Open File Table:
- Đây là một bảng cấp hệ thống, chứa thông tin về tất cả các file đang được mở trên hệ thống.
- Mỗi mục trong bảng này chứa thông tin như quyền truy cập file (đọc, ghi, v.v.), trạng thái hiện tại của file (vị trí con trỏ file), và thông tin về khóa file.
- Khi một file được mở nhiều lần, có thể bởi nhiều tiến trình khác nhau, mỗi tiến trình sẽ có FD riêng nhưng chúng có thể tham chiếu đến cùng một mục trong Open File Table.
- I-node Table:
- I-node Table chứa các I-node, mỗi I-node chứa metadata của một file cụ thể. Metadata này bao gồm các thông tin như quyền truy cập, chủ sở hữu file, nhóm, kích thước file, thời gian tạo và sửa đổi, cũng như các con trỏ đến dữ liệu thực tế của file.
- Khi một file được mở, kernel sẽ tìm I-node tương ứng trong bảng này dựa trên đường dẫn file.
- I-node không lưu trữ tên file, mà tên file được lưu trong thư mục và liên kết với I-node.
Cơ chế này giúp Linux quản lý file một cách hiệu quả và linh hoạt, cho phép nhiều tiến trình truy cập và thao tác với cùng một file mà không gây xung đột.
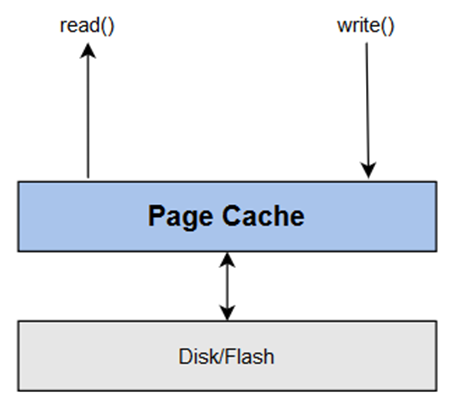
Quá trình đọc và ghi dữ liệu trong hệ thống Linux thông qua các lệnh read() và write() là một phần quan trọng của cách kernel xử lý dữ liệu. Quá trình này liên quan đến Page Cache, một phần của bộ nhớ được sử dụng để lưu trữ dữ liệu của các file được truy cập thường xuyên, nhằm giảm thời gian truy cập dữ liệu từ đĩa cứng. Dưới đây là mô tả tổng quan về quá trình này:
- Xác định Page Cần Đọc:
- Khi một tiến trình yêu cầu đọc dữ liệu từ file thông qua
read(), kernel trước tiên xác định page (đơn vị quản lý bộ nhớ trong kernel) chứa phần dữ liệu cần đọc.
- Khi một tiến trình yêu cầu đọc dữ liệu từ file thông qua
- Kiểm Tra Page Cache:
- Kernel sau đó kiểm tra xem dữ liệu đó có tồn tại trong Page Cache hay không. Page Cache là một khu vực bộ nhớ được sử dụng để lưu trữ các page được đọc từ đĩa, giúp tăng tốc độ truy cập dữ liệu.
- Đọc Dữ liệu Từ Page Cache:
- Nếu page cần đọc có trong Page Cache, kernel sẽ trực tiếp đọc dữ liệu từ đó và truyền nó về userspace, nơi tiến trình đang chạy.
- Xử Lý Khi Page Không Có Trong Page Cache:
- Nếu page không có trong Page Cache, kernel sẽ đọc page từ vùng nhớ vật lý (đĩa cứng, SSD, v.v.) vào Page Cache. Sau đó, dữ liệu từ page mới được đọc này sẽ được truyền đến userspace.
- Ghi Dữ liệu Vào Page Cache:
- Khi một tiến trình sử dụng
write()để ghi dữ liệu, kernel đầu tiên ghi nội dung vào Page Cache.
- Khi một tiến trình sử dụng
- Đồng bộ Hóa Dữ liệu Với Đĩa Cứng:
- Dữ liệu trong Page Cache sẽ được ghi trở lại vào vùng nhớ vật lý (đĩa cứng) một cách định kỳ, hoặc khi các lệnh như
sync()hoặcfsync()được sử dụng. Điều này đảm bảo rằng dữ liệu trên đĩa cứng được cập nhật và phản ánh các thay đổi mới nhất.
- Dữ liệu trong Page Cache sẽ được ghi trở lại vào vùng nhớ vật lý (đĩa cứng) một cách định kỳ, hoặc khi các lệnh như
Page Cache trong Linux là một phần của bộ nhớ chính (RAM) của hệ thống. Nó được sử dụng bởi kernel để lưu trữ nội dung của các file và các block dữ liệu được truy cập gần đây từ các thiết bị lưu trữ như ổ cứng hoặc SSD. Mục đích chính của Page Cache là cải thiện hiệu suất bằng cách giảm thiểu số lần cần truy cập vào thiết bị lưu trữ chậm hơn, như ổ cứng, bằng cách giữ các dữ liệu được sử dụng thường xuyên trong RAM, nơi truy cập nhanh hơn nhiều.
Khi một file được đọc, dữ liệu từ file đó được nạp vào Page Cache. Nếu tiến trình cần truy cập vào file đó lại, kernel sẽ kiểm tra xem dữ liệu đã có trong Page Cache chưa thay vì đọc trực tiếp từ thiết bị lưu trữ. Điều này giúp tăng tốc độ đọc dữ liệu vì truy cập RAM nhanh hơn nhiều so với truy cập ổ cứng.
Tương tự, khi dữ liệu được ghi vào file, nó thường được ghi vào Page Cache trước và sau đó mới được đồng bộ hóa với thiết bị lưu trữ theo các quy tắc nhất định, giúp tối ưu hóa hiệu suất ghi.
Page Cache được quản lý một cách linh hoạt bởi kernel, với các cơ chế như swappiness và cơ chế làm sạch cache, để đảm bảo rằng bộ nhớ được sử dụng hiệu quả, cân nhắc giữa nhu cầu của các tiến trình và cần thiết của việc lưu trữ tạm thời dữ liệu.